SQL窗口函数
1. 前序
sql 函数相信大家都清楚,比如聚合函数 SUM、AVG、SUM、MAX 等等。今天要讲的是窗口函数,可能大多数人都不太了解这是什么,因为我也是刚刚学到的新知识哈哈,以往看过的一些视频和文章都没有讲过。
本文基于 Postgresql 13.3演示,MYSQL8和Oracle也有窗口函数
什么是窗口函数?
窗口函数(有的地方也叫开窗函数,聚合函数是闭窗函数)也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据进行实时分析处理。窗口函数其实就是一个分组窗口内部处理每条记录的函数,这个窗口也就是之前聚合操作的窗口,刚开始可能有点难理解,窗口函数是基于结果集进行运算的。它将计算出的结果合并到输出的结果集上,也就是说不会影响原数据
它和聚合函数的区别?
- 聚合函数是将多条记录聚合为一条;而窗口函数是每条记录都会执行,不会影响原数据
- 聚合函数也可以作用于窗口函数
执行时机?
窗口函数的执行在WHERE、GROUP BY、HAVING以及聚合函数之后,意味着不能作用于那些子句中
场景?
比如我们需要获取收入增长的一个情况,比如要获取每个班级的前几名学生的成绩,使用传统 sql 固然能实现,但是都比较麻烦
2. 语法
1 | |
- window_function() 是窗口函数
- OVER 是窗口函数的关键字;
- PARTITION BY对结果集行进行分区
- ORDER BY 对分区数据进行排序
- 最后的 ROWS | RANGE 及后面的就是窗口子句,用作对窗口帧的处理
窗口函数有哪些?
窗口函数:RANK、DENSE_RANK、ROW_NUMBER、FIRST_VALUE、LAST_VALUE 等函数
聚合函数:SUM、AVG、MAX 等
3. 实操
初始化数据
1 | |
1 | |
现在有一个需求,查询学生名,科目,成绩,以及科目平均成绩,现在使用两种方式看看区别
普通查询
1 | |
窗口函数
1 | |
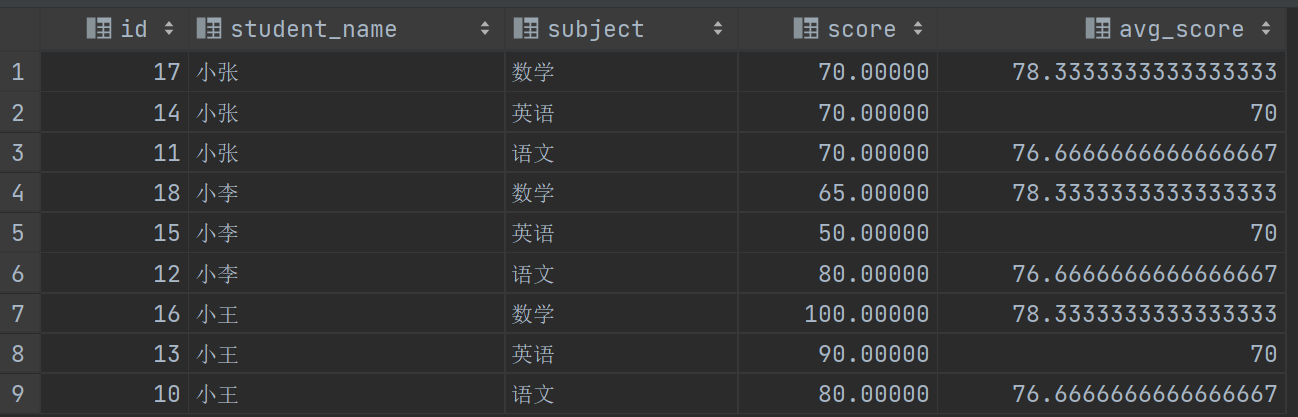
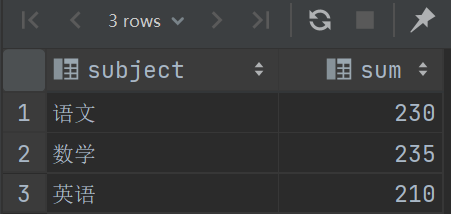
我们可以看到窗口函数很简洁,对最后结果集进行分组,那此时就有三组,然后聚合求平均值,并且保留每条记录
通过 PARTITION BY 分组后的集合就叫窗口,这里的 147 就是一个窗口,然后求平均值,(70+65+100)/3~=78.33333333333333,其他两个窗口一样的
第二个需求,查询每科成绩排名第一的学生名,科目,成绩,现在使用两种方式看看区别
普通查询
1 | |
窗口函数
1 | |
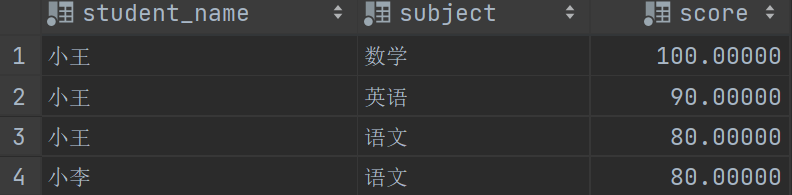
乍一看可能觉得窗口函数更复杂,但是理解后会发现窗口函数很简单,普通查询我们需要判断一下在同一个科目下有没有分数比我当前大的,小于1那就是没有对吧,那我就是最大的,所以就能拿到第一
再来看窗口函数,窗口函数是对结果集进行处理的,我们先根据科目进行分组,再对成绩进行排序(窗口函数内的 ORDER BY 就是对窗口进行排序),就能拿到每科的成绩排名了,然后取第一个,这时我们怎么知道谁是第一个呢,这时候序号函数就出场了,RANK 函数是一个序号函数,它可以对数据进行排序,然后我们取第一个不就能拿到成绩最高的了吗,如果有重复的,那么他们的序号是一样的,细心的小伙伴可能会发现语文这一科的分数有相同的,但是第三条记录的序号是3为什么不是2呢?后面会对序号函数进行讲解
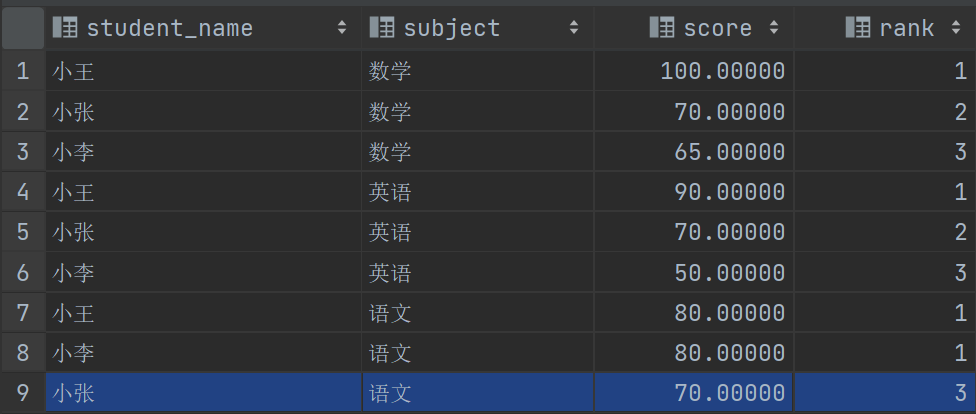
再如给查询结果加序号,你会怎么做?
使用窗口函数非常简单
1 | |
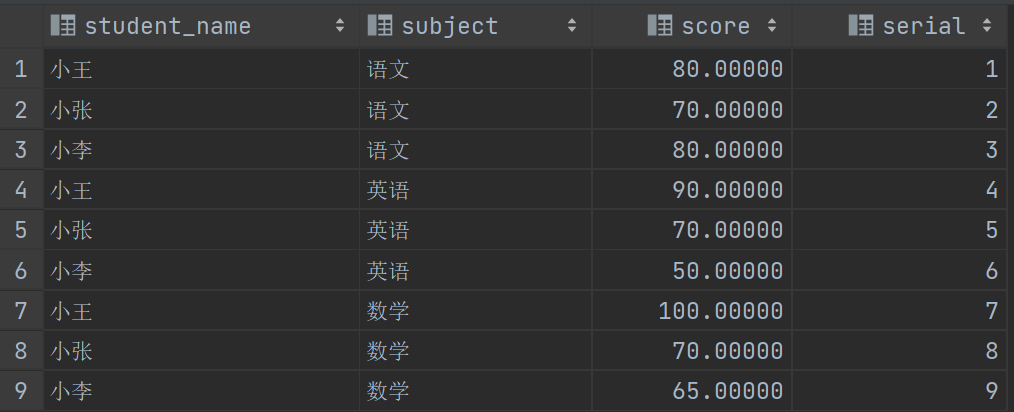
这里省略了分组和排序,没有分组说明所有数据都是一组的,没有排序就是默认顺序,然后使用了一个 ROW_NUMBER函数,这也是一个序号函数
再如计算每科的累加总分,对比一个哪一科总分数最高?(可拓展为公司各个部门销售业绩对比) 发现多此一举了
1 | |
窗口函数是对结果集进行处理的,所以不能在原语句上进行分组(sql 执行逻辑是这样的,就像为什么排序后不能分组一样,没意义!)
4. 窗口函数
4.1 RANK、DENSE_RANK、ROW_NUMBER
上面已经讲过了两个序号函数,序号函数其实就是给数据行分配一排名,下面介绍三个内置的序号函数(更多窗口函数点这[1]),它们的区别如下
- RANK 返回当前行的排名,包含间隔,如果出现并列情况(比如成绩相同),那么并列的序号一样,并且会占用下一个名次的位置,比如1 2 2 4
- DENSE_RANK 返回当前行的排名,包含间隔,如果出现并列情况(比如成绩相同),那么并列的序号一样,不会占用下一个名次的位置,比如1 2 2 3
- ROW_NUMBER 返回其分区内的当前行数,从1开始计数,忽略并列情况,比如 1 2 3 4
示例
1 | |
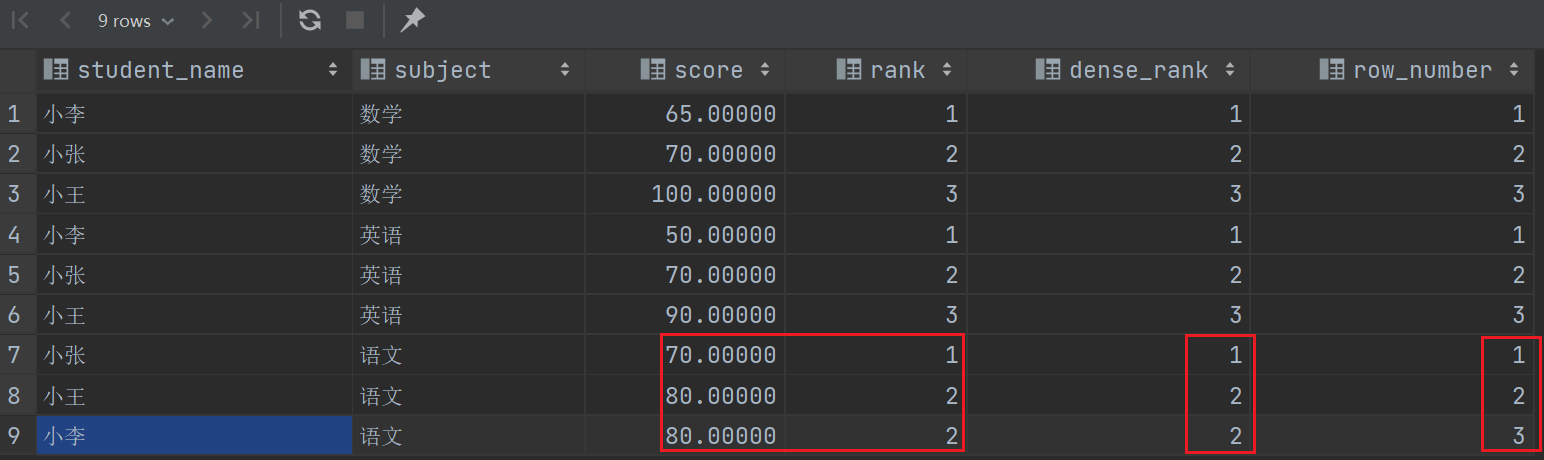
这里可以看出 ROW_NUMBER 与其他两个函数的区别了,但是看不出其他两个函数的区别,我们添加一条数据再来看看
1 | |
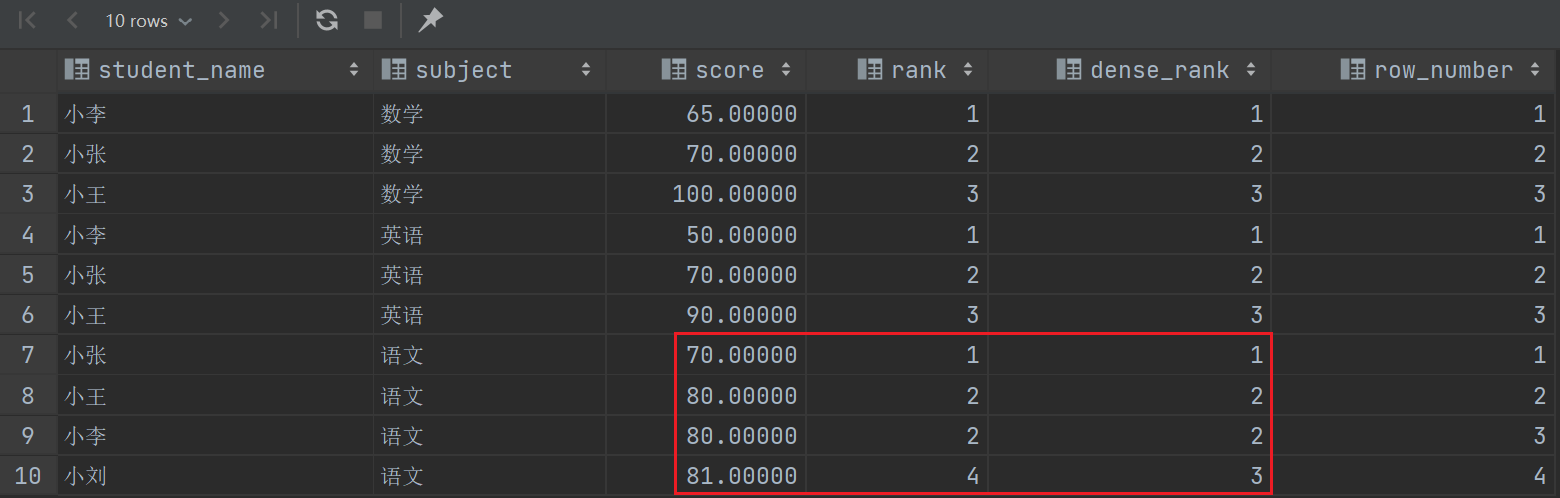
跟预期一样 RANK会占有下一位的名次,而 DENSE_RANK 不会,我们可以根据实际业务去选择哪个序号函数。
最后看一下不加排序的效果
1 | |
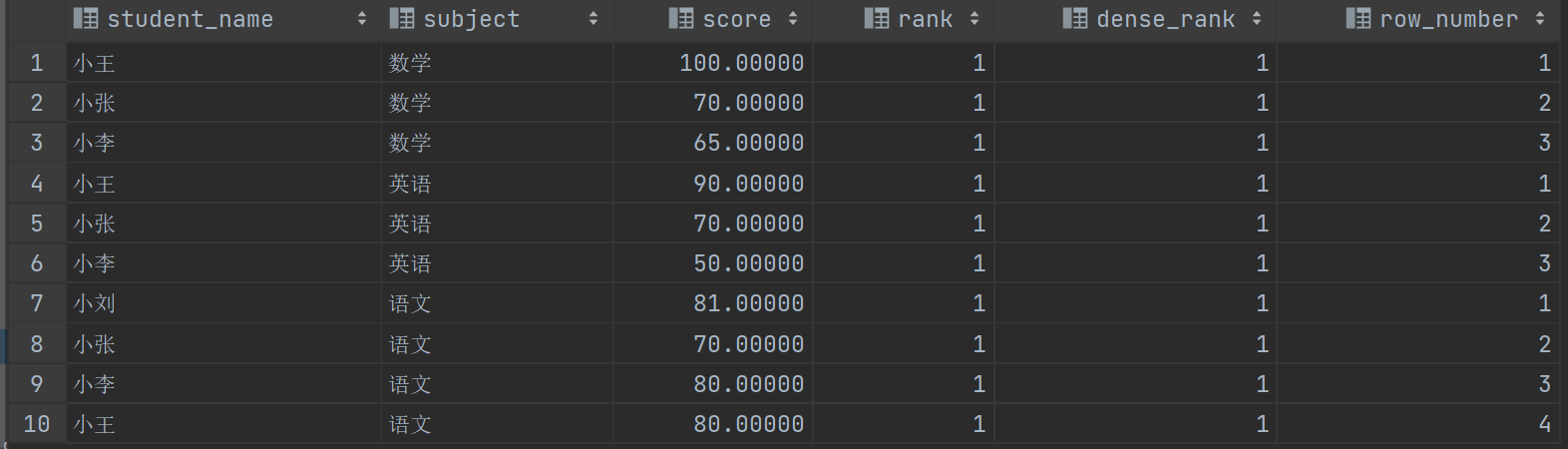
可以看到没有排序时都是同等行(没有指定具体字段),RANK 和 DENSE_RANK 都是1,但是 ROW_NUMBER 不一样,他返回的是行数不是排名,所以不管排序与否都会递增计数。
4.2 FIRST_VALUE、LAST_VALUE、NTH_VALUE
1 | |
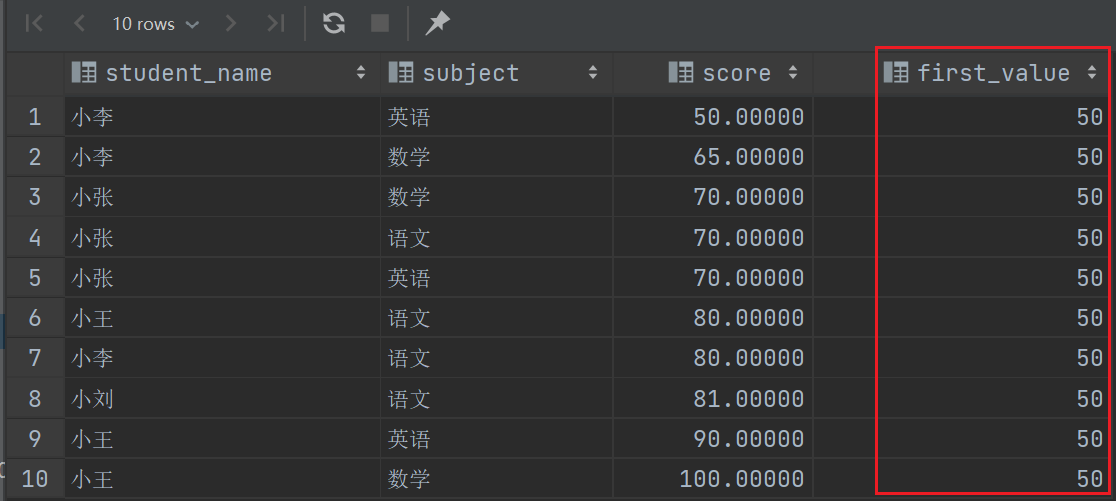
如果分区了,那么取的就是每个分区的第一行。
1 | |
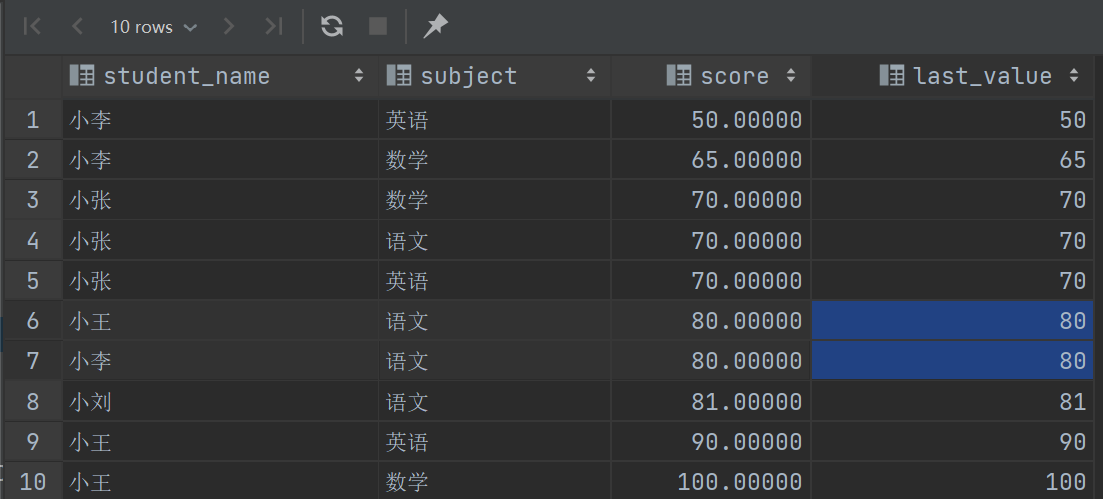
这次结果并没有在预料之中,拿到最后一行的结果跟当前行一样,这里有一个注意项,first_value、last_value和nth_value只考虑“窗口帧”内的行,关于窗口帧在下面有讲到,什么意思呢,第一行的窗口帧就是本身,那最后一个还是自己,到了第二行窗口帧就包括{1,2}行了,此时最后一个还是自己,到了第三行窗口帧就包括{1,2,3,4,5}行了(下文有讲到为什么),此时最后一个还是自己,后续相同,所以会造成这种情况。我们只需要想个办法让每一行的窗口帧汇集所有行集即可,那么每次都能拿到真正意义上的最后一个
窗口帧子句上场了,窗口帧子句就是对我们的窗口做后续操作的,后面再细讲
1 | |
将窗口中的第一行和最后一行分别设置为分区中的第一行和最后一行,这时就能达到效果了
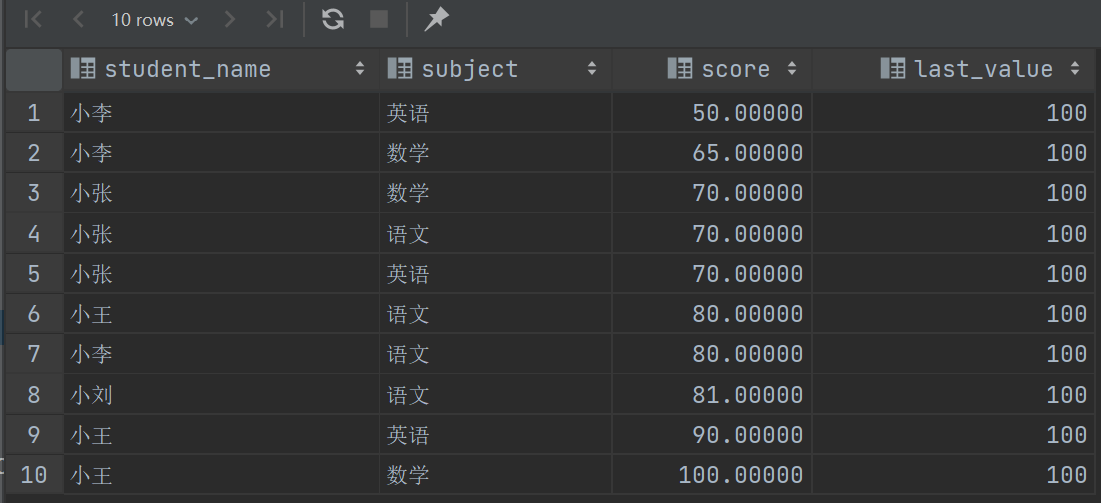
1 | |
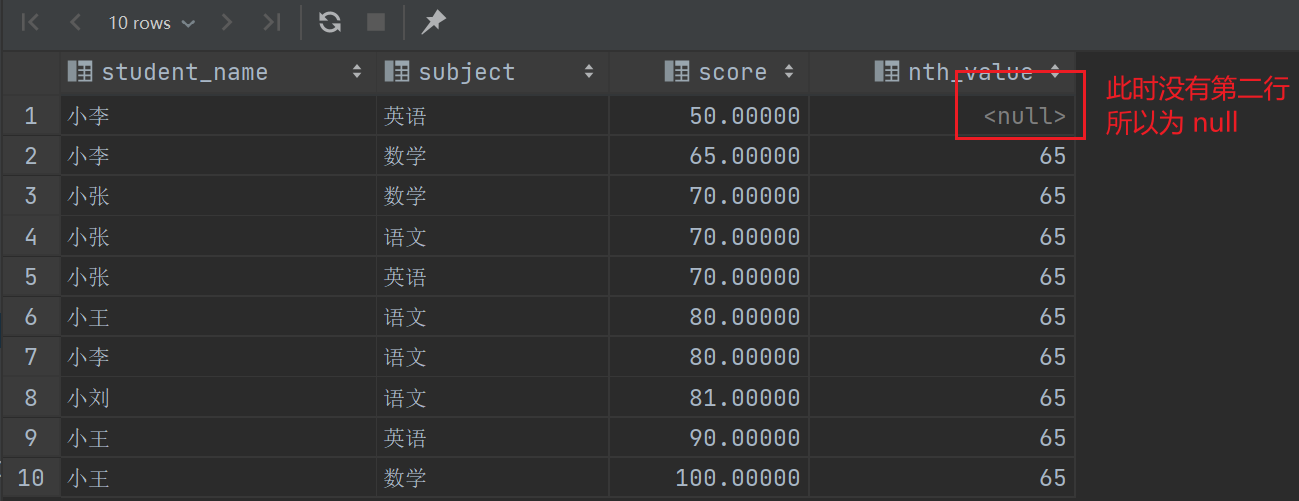
4.3 窗口帧
如果行的顺序不重要时ORDER BY可以忽略。PARTITION BY同样也可以被忽略,在这种情况下会产生一个包含所有行的分区
窗口帧是一个重要的概念,对于每一行,在它的分区中的行集被称为它的窗口帧 ,一些窗口函数只作用在窗口帧中的行上,而不是整个分区。默认情况下,如果使用ORDER BY,则帧包括从分区开始到当前行的所有行,以及后续任何与当前行在ORDER BY子句上相等的行。如果ORDER BY被忽略,则默认帧包含整个分区中所有的行,这是摘抄文档的,有点难懂,举个例子
1 | |
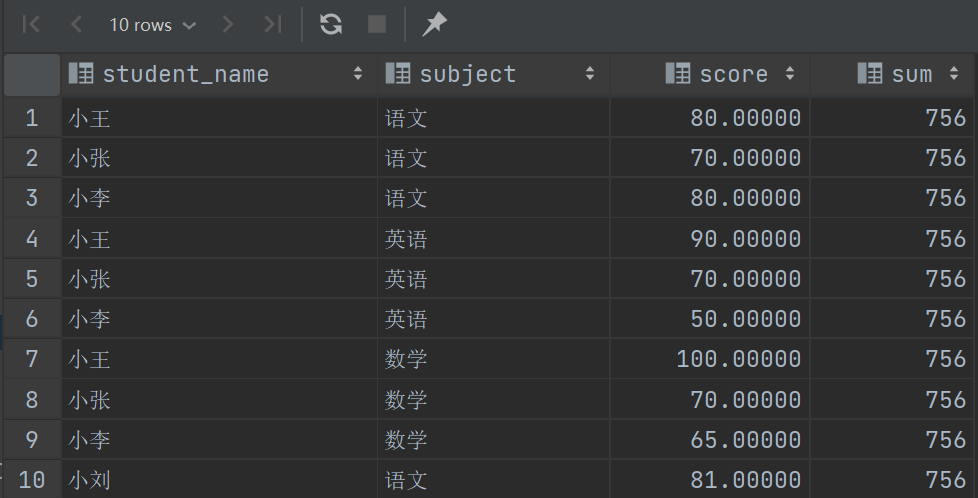
这时没有使用 PARTITION BY 和 ORDER BY ,那此时就有一个包括所有行的分区,默认帧就包含所有行集,每一行的窗口帧都包含所有行集,那么 SUM 就是对所有行进行计算,所以每一行都是 sum 后的结果。
使用 ORDER BY 看看
1 | |
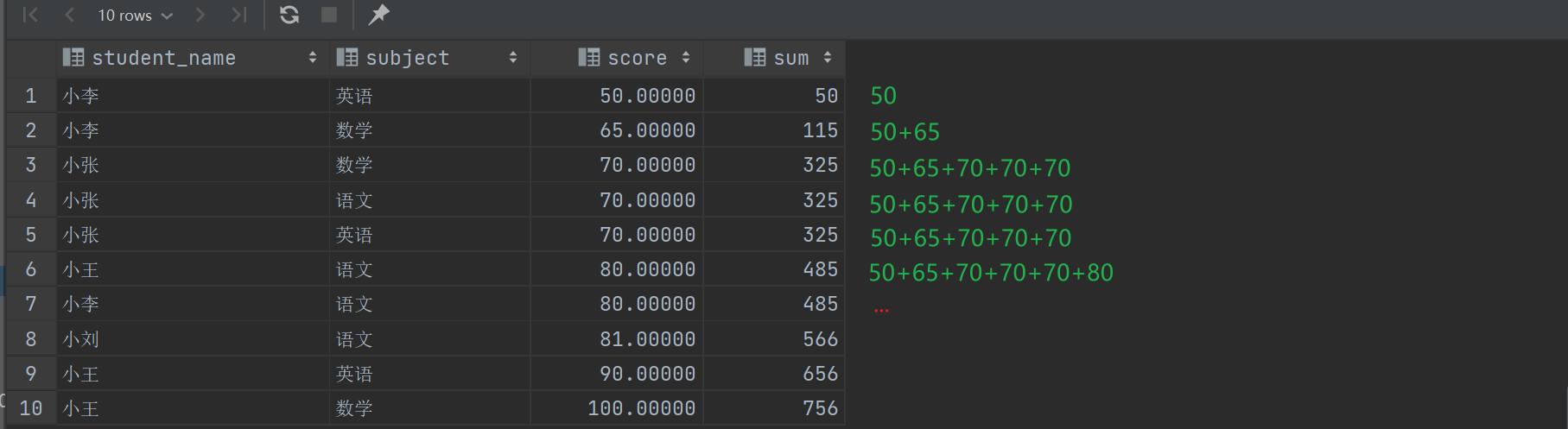
第一行时窗口帧只包括第1行,到了第2行时窗口帧就包括第1-2行,到了第三行时就包括1-5行了,因为后续任何与当前行在ORDER BY子句上相等的行也在窗口帧的范围内,所以它们都是325,后续一样累加。
默认情况下任一行的窗口帧,必然含有本行,窗口帧内的元素数必然大于等于1,必然小于等于本行所在分区的全部行数
4.4 窗口帧子句
窗口帧(帧就是 Frame)上面讲过了,有时候并不能拿到我们想要的 Frame,这个时候就需要我们去使用 Frame 子句进行处理了,Frame 子句分为两种
ROWS根据当前行中的物理行偏移数 (ROWS) 表示窗口的大小RANGE根据当前行中值的数据值偏移范围 表示窗口的大小
还有定义窗口帧开始行和结束行的子句
PRECEDING 子句 PRECEDING 子句用于使用当前行作为参照点来定义窗口的第一行。起始行可根据当前行之前的行数来表示。例如,
5 PRECEDING设置窗口从当前行之前的第五行开始。UNBOUNDED PRECEDING 用于将窗口中的第一行设置为分区中的第一行。
FOLLOWING 子句 FOLLOWING 子句用于使用当前行作为参照点来定义窗口的最后一行。最后一行可根据当前行之后的行数来表示。
UNBOUNDED FOLLOWING 用于将窗口中的最后一行设置为分区中的最后一行。
BETWEEN 子句 BETWEEN 子句用于使用当前行作为参照点来定义窗口的第一行和最后一行。第一行和最后一行可分别根据当前行之前和之后的行数来表示。例如,
BETWEEN 5 PRECEDING AND 5 FOLLOWING设置窗口从当前行之前的第五行开始,结束于当前行之后的第五行。BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 用于将窗口中的第一行和最后一行分别设置为分区中的第一行和最后一行。这等同于未指定 ROW 或 RANGE 子句时的缺省行为。
如果不指定 Frame 子句,则默认采用以下的 Frame 定义:
- 若不指定
ORDER BY,默认使用分区内所有行RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING - 若指定了
ORDER BY,默认使用分区内第一行到当前值RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
之前测试 LAST_VALUE 函数的时候指定了排序,所以造成了每次最后一行都是当前行
举个例子
1
2
3SELECT student_name, subject, score, LAST_VALUE(score) OVER w1
FROM score S WINDOW w1 AS (ORDER BY score ROWS BETWEEN 1 PRECEDING AND 3 FOLLOWING);
-- 从当前行之前的第一行开始,结束于当前后之后的第三行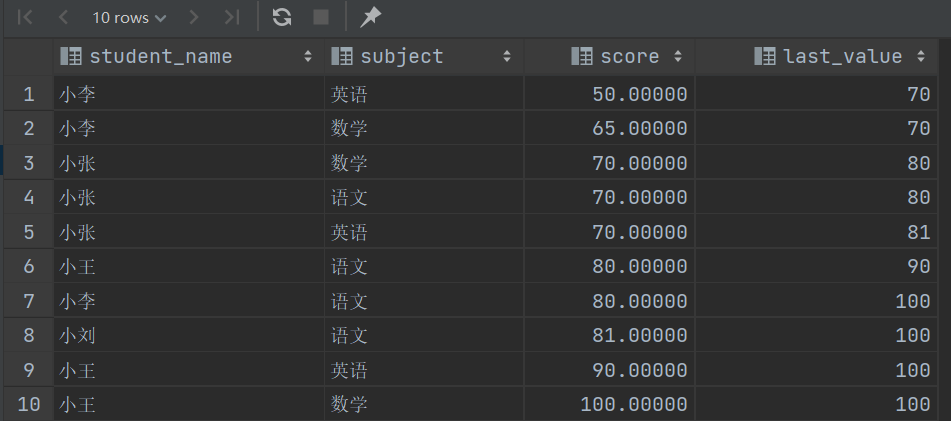
第一行 Frame 范围那就是 {1,2,3,4},最后一个就是70,第二行范围就是{1,2,3,4,5},最后一个也是70,第三行范围{2,3,4,5,6},那最后一个值就是80了,一次类推就很容易理解了
上面是 ROWS 演示,再来试试 RANGE 看有什么不一样
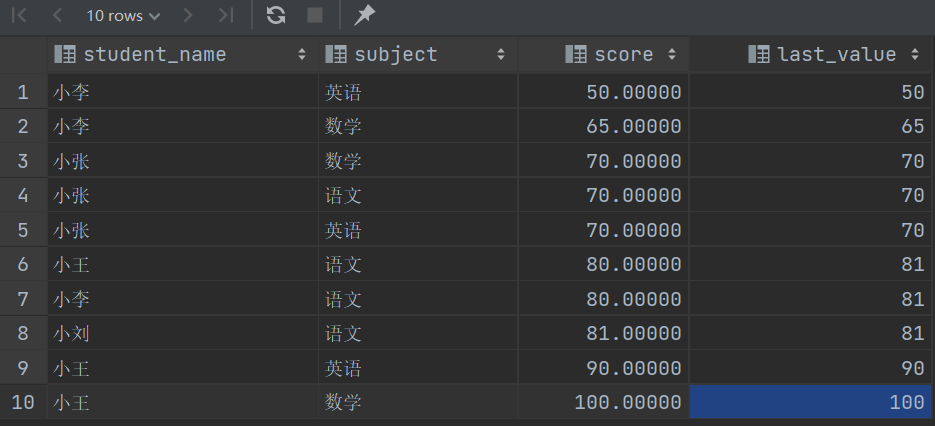
可以看到前面都没什么区别,到了80、81这里才有点区别,上面说过了 RANGE 是根据当前行的值来进行偏移的,这个值就是 score ,那么第一行的范围就是(50-1)到(50+3),差距太大,所以说前面几行都没什么变化,我们直接从第6行开始看,范围是(80-1)到(80+3),所以最后一个值是81。一句话,实践出真理
- 若不指定
5. 总结
不局限于 上面的示例,比如使用各种聚合函数,比如不分区排序,分区排序,分区不排序等等都会发生意想不到的效果,多去尝试就能发现新大陆,下次会带来 SQL 递归
6. 参考
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!